IOMesh Pod HA: Enhancing Kubernetes Cluster Availability
Many enterprises leverage persistent storage for Kubernetes to enhance the availability and reliability of their Kubernetes clusters. However, some may encounter issues similar to the following:
- If a Kubernetes node fails, Pods with the PVC access mode set to Read-Write-Once (RWO) may fail to be migrated to other nodes, causing downtime. This happens because the system cannot bind the PVC to the Pod on the new node.
This problem is caused by the Kubernetes default mechanism. With an improved Pod High Availability (HA) feature, IOMesh prevents this issue and advances Kubernetes cluster availability. In this article, we will dive into the implementation of the Pod HA feature in IOMesh.
Default Kubernetes Behavior: Potential HA Failures with RWO PVCs
Kubernetes has default mechanisms that can lead to high availability failures for Pods when using RWO-type PVCs. If a Kubernetes worker node fails, the associated VolumeAttachment of an RWO PVC may not be deleted as intended due to these mechanisms. This could cause the system to mistakenly believe that the original Pod still uses the PVC, preventing the PVC from being bound to the Pod on the new node and ultimately impacting Pod availability.
The whole process is as follows:
- One minute after the node failure, users will find that the status of the failed node has changed to NotReady by running the command “kubectl get nodes”.
- Five minutes after the node failure, all Pods on the NotReady node will change to the Unknown or Terminating state.
- StatefulSets have stable identifiers and by default will not rebuild Pods that have changed to the Terminating state on other healthy nodes. Kubernetes will not enforce the deletion of the Pod, either.
- Deployments do not have stable identifiers, so they will create new Pods on other healthy nodes to maintain the desired number of replicas. At this point, the failed Pods will remain in the terminating state and won't be deleted by Kubernetes. In this situation, if the failed Pods are using RWO-type PVCs, these PVCs won't be able to bind to new Pods, causing the new Pods to get stuck in the ContainerCreating state unless there is manual intervention or some other action.
Critical Problem: Lack of Automatic Unbinding Between Pod and Failed Node
Pod HA failure can be attributed to the incorrect decision made by the Kubernetes attach/detach controller (hereinafter referred to as A/D controller). The A/D controller is a built-in controller in Kubernetes, responsible for deciding which node the volume should be attached to or detached from according to the Pod scheduling decisions issued by the kube-scheduler.
To make an effective intervention, we analyzed the A/D controller’s working principle. This can be simplified as follows:
- When the A/D controller starts up, it retrieves information from the API server about which nodes have which volumes bound to them and saves this binding information and related details in the actualStateOfWorld structure.
- After that, the A/D controller periodically pulls the scheduling information of the Pods from apisever and caches the mapping relationship between Pods and nodes to which Pods are expected to be or have been scheduled in the desiredStateOfWorld structure.
- After that, the A/D controller periodically pulls the scheduling information of the Pods from apisever and caches the mapping relationship between Pods and nodes to which Pods are expected to be or have been scheduled in the desiredStateOfWorld structure.
- Based on the results of Step 3, the A/D controller updates cached data in actualStateOfWorld to the latest state When creating PVC via CSI, the attachment operation will generate the corresponding VolumeAttachment. Once the creation of the VolumeAttachment is monitored, the csi-attacher sidecar will call the ControllerPublishVolume RPC.
Now, let’s reframe the story of Pod HA failure in light of the working principle of A/D controller: Suppose Deployment-A manages Pod-A on Node-A and Pod-B on Node-B, and both Pods are bound to an RWO-type PVC. If Node-A loses network connectivity, Pod-A will transition to the Terminating state. In this situation, Kubernetes does not enforce the deletion of Pod-A, so the binding relationship between Pod-A and Node-A still exists in the desiredStateOfWorld cache data of the A/D controller, which will not trigger the deletion of the corresponding VolumeAttachment on Node-A. At this point, Deployment-A detects that the number of running replicas is lower than expected and decides to rebuild Pod-A on Node-C. Due to the default Kubernetes mechanisms for PVCs of RWO types, the A/D controller assumes that the corresponding VolumeAttachment still exists on Node-A and therefore rejects the binding request for Pod-A to the new node. As a result, Pod-A remains stuck in the ContainerCreating state, which eventually leads to high availability failure.
Solution: Deleting VolumeAttachment vs. Deleting Pod
Based on the analysis above, it can be concluded that in order to successfully establish a new binding, either the existing VolumeAttachment needs to be deleted or it should be removed once Pod-A enters the Terminating state.
Initially, we attempted the first option: manually deleting the VolumeAttachment on Node-A to enable the reconstruction of Pod-A on Node-C. This approach yields immediate results and can be done automatically by adding a VolumeAttachment controller within the CSI driver.
However, after analyzing the code of the A/D controller, we found that the user-initiated deletion of VolumeAttachment is an unexpected behavior and may have some risks; When the A/D controller deletes a VolumeAttachment, it updates the cached information in actualStateOfWorld. However, if a user manually deletes a VolumeAttachment, the A/D controller will not be aware of it, resulting in inaccurate cached information in actualStateOfWorld and potentially leading to incorrect decisions by the A/D controller.
Therefore, we believe that it is better to delegate the deletion of the Pod to CSI, allowing the A/D controller to autonomously complete the detach and cache update process. This is how we implement the Pod HA feature in IOMesh.
Pod HA in IOMesh: Enhancing Availability for Kubernetes Clusters
To prevent the aforementioned issues and enhance cluster high availability, we introduce node awareness to IOMesh, allowing for automatic deletion* and rebuilding of Pods during node failures. * This function is enabled by default. Users can choose to disable this feature manually.
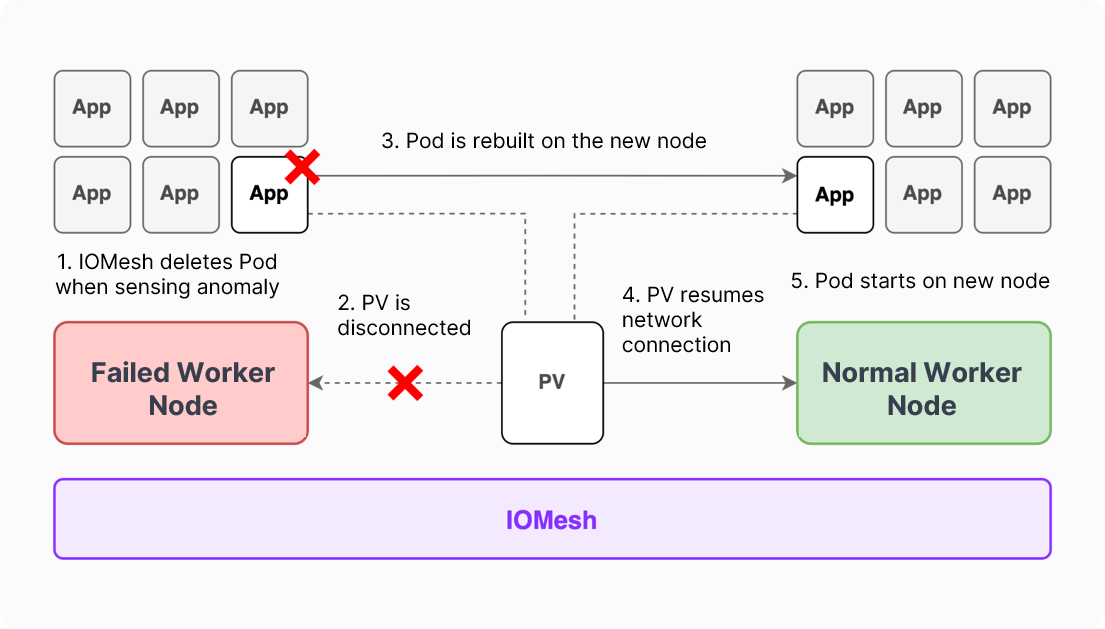
The implementation process of this mechanism is as follows:
- When the IOMesh CSI driver detects that the status of a Kubernetes node has changed from Ready to NotReady, it begins to monitor the node status periodically with an interval of 30 seconds by default.
- If the returned results show NotReady 3 times (default, configurable) consecutively, IOMesh will automatically perform Pod deletion. Pods on the node that meet the following conditions will be deleted:
- The Pod is bound to at least one PVC, and all of its PVCs are created via the IOMesh CSI driver.
- The Pod is not in the Running state.
- There is at least one healthy node in the cluster, and the Pod can be scheduled to that node (there is no relevant affinity or stain conflict).
- Check if the ownerReferences (deployment or statefulset) of the Pod meet the startup parameter settings.
- After the Pod is deleted, the A/D controller will automatically perform detachment, including removing the binding relationship between the deleted Pod and the failed node when periodically updating desiredStateOfWorld, unbounding the PVC and the Pod, deleting the VolumeAttachment on the failed node, and updating the information of actualStateOfWorld.
- After the detachment operation is complete, the Pod will attach to the new node and thus is successfully rebuilt on the healthy node.
The entire Pod HA process takes 7 minutes and 30 seconds. Out of this duration, 1 minute and 30 seconds is the default monitoring time from the node failure to the Pod deletion by CSI. Users can set this time length when configuring the IOMesh CSI driver. The remaining 6 minutes is the fixed time required for PVC detachment from the failed node, which is a predetermined parameter set by Kubernetes for the A/D controller.
To learn more about IOMesh, please refer to IOMesh Docs, and join the IOMesh community on Slack for more updates and community support.